Docker Networking Vulnerability
Background
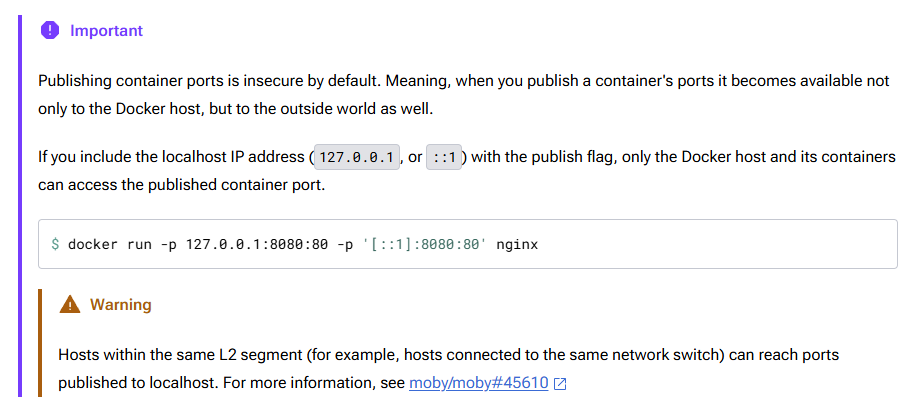
Docker v28 was released on 20/02/2025 to very little fanfare despite fixing a networking weakness that had been documented since May 2023. The vulnerability would allow attackers on the local network to access services even when they were bound to localhost. The warning below was present on multiple pages of the official documentation (for those who read documentation), with additional details at moby#24510.
What Did It Mean?
L2 segments: Networks which route directly at Layer 2 (Data Link Layer) of the OSI Model. In practice, this means the host is accessible by its MAC Address (either directly or via a L2 Router).
Ports published to localhost: Container ports which were bound to the “private” loopback interface of the host. This is intended that only users on the machine itself could access the exposed services (compared to services intentionally shared with other network-based users).
—
Together, this typically meant that attackers on the same subnet or switch could access services that you published to the loopback (or any other) interface.
Who Was Affected?
This primarily affected systems which used the localhost bind as a security control (assuming that only trusted parties could access the local interface). Examples of this would include developers writing and testing their applications at a coffee shop, workstations running applications published via Docker Hub, or on-premise servers running dockerised solutions (either internally managed or vendor bundled platforms).
Consider a hypothetical web application that has both user facing (all interfaces) and administrative (localhost) web portals. An attacker could leverage this weakness to access the administrative portal from another machine on its subnet.
What Caused It?
The Docker Daemon is an orchestration layer for managing isolation tools built into the Linux Kernel (namespaces, control groups) and host networking (iptables). For this issue, we will focus on the networking side.
Firstly, Docker enables a networking flag called ip_forward. This flag is typically used for routers (e.g. forwarding packets from your home Wi-Fi out to the internet). It instructs the networking stack to accept packets destined for other machines and to forward them on according to its own routing rules. Docker uses this to assist routing in and out of container networks.
Secondly, Docker creates DNAT (Destination Network Address Translation) rules for each exposed port (regardless of which interface it was bound to). This tells the network stack to rewrite the target IP of packets to match the container’s private IP (otherwise the container would ignore the request due to a mismatched IP).
The combination of these settings meant that packets targeted at the host’s network interface (MAC address) using the container’s address (IP) would be forwarded into the container regardless of the bind address.
Docker runs a network proxy service (docker-proxy) per binding to listen on the requested bind and forward packets on; however, we fully bypass this service by using the native host routing stack.
How They Fixed It
The fix ended up be reasonably simple, they now add additional iptables rules for each bind that will drop any packets destined for the bound container/port if it did not originate from the expected network interface (using the “raw” table “OUTPUT” chain - for those interested in the finer details).
Let’s Exploit It
(Note: This section is Linux specific, although detection will work cross-platform).
Detection
Before we attempt to exploit the vulnerability, we should confirm that the target is actually vulnerable to it. The network scanning tool nmap has a script that does this. As it requires a target address, we will use the default Docker network for scanning (172.17.0.0./16) where 172.17.x.1 maps to the Docker host itself.
sudo nmap -sn -n --script ip-forwarding --script-args target=172.17.0.1 192.168.0.0/24
(replacing 192.168.0.0/24 with your intended range).
This requires root (sudo) access because it leverages raw sockets.
The Basics
Ethernet frames contain a link layer address (MAC) and payload. For TCP/IP packets, the payload then includes a network address (IP). This allows us to create packets with mismatched MAC and IP combinations to influence how the host (MAC address) handles the packet.
Under normal operation, the following protocols are involved in managing these pairs:
- DHCP (broadcast) - “Can someone suggest an IP for me to use so that I don’t conflict with anyone else on the network” -> “Here’s a free IP: x.x.x.x, its on subnet x.x.x.x/x, and you should send any unknown destinations to the gateway x.x.x.x by default”.
- ARP (broadcast) - “I have this IP address (and implicitly this MAC), who has IP address x.x.x.x” -> “I have IP address x.x.x.x (and implicitly MAC Address)”.
So a new client will conduct a DHCP request, the DHCP server will provide an IP and suggested routing information which will then be stored in the workstation’s “routing table”. Any network requests on the same subnet will conduct an ARP request so that the packet can be sent directly to the target MAC address (either directly on a switch, or via Layer 2 routing on a router).
To exploit the Docker weakness, we can either inject raw packets into the network or overwrite the supplied routing table rules. Of these options, leveraging the system’s existing network stack is likely to be more predictable and reliable.
The Naive Approach
The most direct approach to rewriting packets is to replace the default routing rule (gateway) to be the IP of the targeted host. This causes all traffic to be routed to the targeted system’s MAC address, but also means you’ll likely lose internet connectivity because it affects all traffic.
An example command for configuring this would be:
sudo ip route add default via {TARGET_IP}
This can be partially mitigated by specifying an IP range instead of “default”; however, it still affects the entire host’s routing and there must be a better way.
The Improved Approach
Similar to Docker, we can create an isolated network environment using Network Namespaces. This means that we can retain normal operation on the host, while rewriting packets within the namespace. An example command flow for configuring this would be:
sudo ip netns add my_namespace
sudo ip link add link {UPSTREAM_INTERFACE_NAME} name my_dev netns my_namespace type macvlan mode private
sudo ip netns exec my_namespace bash
dhclient -1 my_dev
ip route change default via {TARGET_IP}
This creates a new namespace (my_namespace), creates a new virtual reference to the existing network interface ({UPSTREAM_INTERFACE_NAME} - e.g. “ens33”) and places it inside our new namespace. We need to “copy” the existing interface because each interface can only exist in a single namespace at a time. We use the “macvlan” type because it provides the required access to Layer 3 routing (MAC Addresses).
“dhclient” (not necessarily installed by default on all linux distributions) provides an IP via DHCP for our new virtual interface and then we can resort to the previous approach of modifying the (now isolated) routing table to redirect traffic.
This means the host retains normal operation AND we can use modified routes from within the namespace, but it has the following downsides:
- Each namespace consumes a DHCP allocation - The “macvlan” device presents itself to the wider network with its own (randomly generated) MAC Address. This creates network noise and could eventually exhaust the DHCP pool if repeated enough times.
- It puts the parent network interface into “promiscuous” mode as it now needs to listen for packets destined to multiple MAC Addresses. This may result in more network processing overheads.
- dhclient (and a few other tools) are not namespace aware, so they write configuration for all namespaces into a common file.
The approach solved problems of host routing contamination, but we can still do better!
The Optimised Approach
While Network Namespaces provide networking isolation from the host, they also introduced a few overheads. We can avoid these overheads by using conditional routing instead.
One approach would be to allocate multiple IP addresses to the same network interface and conditionally route traffic based on which one we bind to. This has a similar problem to the previous option where we need to consume a range of IP addresses from the environment. Additionally, many tools do not provide the option to select the source binding port.
A better approach is to use “cgroups” (control groups) - a Linux Kernel isolation feature (also used by Docker) to add limits, prioritisation, and accounting on resources such as cpu, disk, and memory. We can use the following process to create new conditionally routed environments:
- Start a new ad-hoc cgroup environment.
- Create an iptables rule that uniquely marks every packet originating from our cgroup.
- Create a routing rule that uses a different routing table if the packet has our cgroup mark.
- Add custom routing rules in our dedicated cgroup routing table.
- (Remove all added rules when the cgroup terminates).
While this seems more complicated than the other options, it provides us the ability to create shell environments with custom routing rules that don’t affect the main host, do not consume IPs from the environment, and can be scaled to many concurrent instances. They are also universally supported by tools due to hooking Kernel level routing.
The following script automates this entire process, either running a given command or dropping down to a user-level shell - both options cleaning up the created rules on close:
Conclusion
Although the patch has been released, it doesn’t necessarily mean that it has been applied to all environments. Some solutions may be months away from having the patch fully propagated into their build cycle.
We now also have a generic script for creating custom routing environments without significant host overheads. This tool can be used to test other systems (routers or otherwise) which have ip_forwarding enabled.
Insecure By Default
While Docker has patched the “warning” from the original screenshot, the “important” remains unresolved as it is an intentional design decision. Let’s also quickly address this while we are thinking about it!
Background
As indicated in the sidenote… “Publishing container ports is insecure by default”. Docker intentionally publishes ports on 0.0.0.0 (all interfaces) by default. This means any services published without specifying an IP to bind to will be automatically publicly accessible.
Mitigation
You can override this behaviour by explicitly setting a bind IP (e.g. 127.0.0.1) on every launch as per the documentation.
Alternatively, you can make it “secure by default” by changing the ip property in the dockerd configuration file to “127.0.0.1” (or your preferred default bind address).
The behaviour can be reverted back on a case-by-case basis by manually binding to 0.0.0.0.
Also… patch to v28, because this mitigation would still be undermined without it!